Blogs

Hydrogen Colors Won’t Save the Planet, But Cutting Carbon Will
The notion of value often stems from scarcity. Ironically, hydrogen, one of the most VALUABLE resources for the clean energy transition, is also the most ABUNDANT element in the universe. This discrepancy is possibly explained by the complexity in obtaining pure hydrogen, which is where the “hydrogen rainbow” concept comes into play.
The “hydrogen rainbow” has become a popular tool in the energy industry to categorize various hydrogen production methods based on their associated carbon emissions. The colors green, blue, turquoise, gray, and brown provide an easy shorthand to distinguish between hydrogen produced from renewable energy, fossil fuels with carbon capture, methane pyrolysis, steam methane reforming, and coal gasification.
However, this color-coding system has likely outlived its usefulness. Instead of clarifying the complexities of hydrogen production, the rainbow oversimplifies the issues, leading to misaligned policies and investments. It may be time to retire the hydrogen rainbow and focus on a more balanced evaluation of hydrogen based on carbon intensity and life-cycle emissions.
The main problem with the hydrogen rainbow is that it implies some colors are inherently “good” and others are “bad.” Green hydrogen, produced from renewable energy, sits at the top of the hierarchy, while gray and brown hydrogen from fossil fuels are thrown to the bottom. This has led to an almost single-minded focus on green hydrogen as the only path forward.
In reality, the situation is far more complex. Not all green hydrogen is created equal—it matters significantly whether the renewable electricity comes from new wind and solar installations or diverts clean energy from the grid. Blue hydrogen, though still reliant on fossil fuels, can achieve relatively low emissions with a high carbon capture rate. Turquoise hydrogen from methane pyrolysis is a promising option that avoids CO2 emissions altogether.
By focusing on colors rather than carbon, we risk making suboptimal decisions. A more useful approach is to examine the specific carbon intensity (kgCO2/kgH2) of each hydrogen production pathway. This would provide a standard, comparable metric to evaluate different projects based on actual emissions performance rather than a categorical color.
The EU is already moving in this direction with its draft regulations requiring hydrogen to achieve a greenhouse gas emission reduction of 70% compared to a fossil fuel baseline to be considered “renewable.” This technology-neutral, performance-based standard will do more to drive innovation and emissions reductions than simply mandating green hydrogen.
Another issue with the hydrogen rainbow is that it ignores the potential for different production methods to evolve and improve over time. Today’s blue hydrogen with 90% carbon capture could become tomorrow’s “teal (blue-green)” hydrogen with 99% capture. Judging colors based on current technology rather than future potential is short-sighted.
We should also recognize that a diversity of low-carbon hydrogen sources will be needed to achieve deep decarbonization. Green hydrogen will play a major role, but it is unlikely to meet all demand, especially for industrial sectors that require high volumes and reliability. Blue hydrogen with carbon capture, turquoise hydrogen from methane pyrolysis, nuclear-powered pink hydrogen, and other solutions will be part of the mix.
The hydrogen rainbow had an important purpose in kickstarting conversations about hydrogen’s role in the clean energy transition. However, as the industry matures, its relevance may reduce. Sophisticated energy and climate policies will look beyond color to the actual carbon impacts. Venture investors will scrutinize projects based on detailed lifecycle assessments, not broad color categories.

Investing in GenAI – Where is the GOLD ??
Source- Generated using Dalle3
Over the last 15 months, since chatGPT became a household name, many entrepreneurs have leveraged GenAI to build cutting-edge technological solutions to solve real-world pain points, thereby driving efficiency, reducing costs and creating value. What has also been fascinating this time is that unlike previous platform shifts (on-prem to cloud, desktop to smartphone)- the cost of embracing change is abysmally low. This has led to a proliferation of solutions across multiple industries and use- cases ranging from expediting drug research to detecting fraud to generating artistic content.
While the progress made in multiple spheres is intellectually stimulating, it comes with challenges for founders and investors. When every company is just an API key away from being a “cutting edge AI company”, how do founders(and investors) look to build and identify truly differentiated use cases? How can incremental value be created if we are reaching a point where advanced generational AI capabilities have become table stakes? Understanding the technology stack of any core AI product is essential to identify white spaces in the AI landscape.
GenAI -Scope for new players to extract value
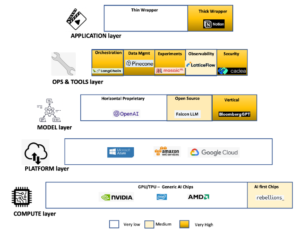
- COMPUTE LAYER
The foundation of the generative AI technology stack starts with specialised computer hardware tailored to manage the computational requirements of AI tasks. Graphics processing units (GPUs) have been instrumental in driving deep learning models’ capabilities by expediting training and inference tasks. In addition to GPUs, other AI-focused silicon and chips, like Google’s Tensor Processing Units (TPUs), contribute to model training and advancement.
Nvidia leads market share in AI chips
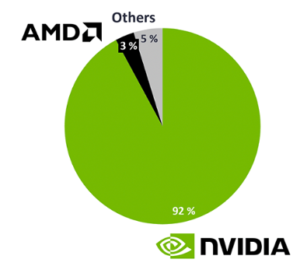 Source- Iotanalytics.com
Source- Iotanalytics.com
i. AI chips
NVIDIA is by far the undisputed leader in AI chips, controlling about 90% of the market share in AI chips. Nvidia could read trends much before LLMs became a household name and invested heavily in RnD and semiconductor technology. The game-changer for them has been the extensive suite of software tools built to augment the hardware capabilities. As a result, NVIDIA’s software tools have become the de facto standard for developing generative AI models. This has made it difficult for other companies to compete with NVIDIA, giving it a significant advantage in developing generative AI services. It will be highly unlikely that any new players other than existing incumbents (including AMD and Intel, besides Big Tech) will be able to cause a significant dent in this market.
ii.”AI first” CHIPs
Many existing AI chips (Nvidia A100, H100) are GPUs initially designed to cater to the high computing requirements of Gaming. The fundamental ground-up design of these chips never fully factored in the specific nuances of LLMs. For example, most current-generation AI chips only have processing logic (driven by billions of transistors) but do not have memory. Many new-age chip companies are working to end the separation between where data is stored (MEMORY) and where data is used( LOGIC), thereby increasing computational efficiency manifold. Another area where new-age firms are quickly ramping up is making task-specific chips that have reduced energy footprint. For example, South Korean startup Rebellion recently raised a $124m round to develop further their “AI first” chipset that is custom-made for task-specific LLMs like computer vision and chatbots, thereby using only a fraction of the training costs of Nvidia and other general purpose AI Chips. This is an area where a lot of innovation, followed by M&As, is likely.
- PLATFORM LAYER
Above the compute layer, lies the cloud platform later. This layer provides applications with the virtualised infrastructure and memory to run their business logic, thereby assisting AI applications in developing, training, and building their models.
The market is dominated by the Big tech players- Amazon (33%), Microsoft (22%) and Google 10%. The balance comprises IBM, Tencent Cloud and Alibaba Cloud. Cloud providers operate on a scale-driven model, where larger size equates to more significant advantages. Additionally, there are benefits to vertical integration, bundling computing power with built-in software, data security, and other related products available on-demand, leading to pricing and performance benefits. Consequently, there is a tendency toward consolidation, at least towards an oligopoly structure. Due to the massive barriers to entry, it is likely to see less VC activity in this layer of the AI tech stack.
Oligopolistic market at Platform Layer
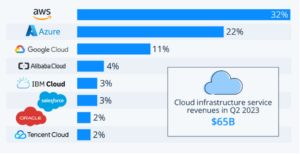
Source – statistica.com
- MODEL LAYER
The core layer of the Gen AI technology stack is formed by a LANGUAGE MODEL that captures patterns and contextual understanding and is trained on large amounts of data. The foundational model may be proprietary or sourced from open-source repositories and model hubs.
i.Horizontal proprietary models
Upon the launch of GPT-3 by OpenAI, there was optimism that it could democratise the technology landscape by potentially challenging the advertising-based Model of Big Tech. However, we have now realised that GenAI is more likely to bolster the dominance of Big Tech firms. These companies possess the resources necessary to develop and sustain the most powerful proprietary AI models, and they are swiftly integrating LLMs into their existing services. Given the significant financing and inference costs associated with training horizontal models, new entrants will face substantial challenges in challenging the incumbents.
b.Horizontal open-source models
The landscape of open-source LLM models has seen significant VC interest due to multiple value offerings. Most open-source models run between 7B and 30B parameters and offer an excellent alternative to customers who can’t afford to pay for traditional foundational models’ training and inference costs. Secondly, LLMs with a few billion parameters can rival the performance of much larger models when trained on extensive datasets. Moreover, remarkable results can be achieved by fine-tuning small LLMs with minimal funding and data. We anticipate that open-source LLMs will drive considerable entrepreneurial and venture capital activity.
c.Vertical models.
Another area of MODELs that will generate significant value is Vertical LLMs. While horizontal LLMs perform well in specific domains, with vertical training, LLMs can gain a deeper grasp of domain-specific terminology, concepts, and context. This specialised understanding empowers them to produce responses that are more accurate and contextually appropriate, meeting the distinct needs of users in that domain. Vertically trained LLMs can grasp the subtle nuances of language used in specialised fields, ensuring the information they provide is dependable and meets the specific demands of professionals. We expect to see more vertically trained LLMs, like BloombergGPT, emerging in highly specialised areas like healthcare and law. Some models may transition into Model as a Service platform or develop into comprehensive solutions with additional applications and integrated tools.
- LLMOps LAYER
In the Gold rush, build shovels ! Datadog, Gitlab, Postman, etc., were investor darlings in the cloud transformation era, and they were essentially a set of tools that helped developers become more productive. Similar trends have started to manifest in the LLM transformation era, too. Building GenAI applications includes many tasks, including development, testing, deployment, security and maintenance. LLM Ops includes all the tools and frameworks needed to help developers manage application lifecycle. New infrastructure technologies face several hurdles to overcome, such as dealing with the unrefined, unorganised nature of image and video data, the static design of current LLM interfaces, the fragmentation of various models (which is expected to persist as models become more specialised for different industries), and the necessity for robust governance to guarantee fair and responsible outcomes. LLM Ops toolkits will be built to solve many of these problems.
Also, the LLMs of the future will be different from the LLMs of today. For example
- LLMs will become the default interaction layer for software programs- they will be able to independently carry out workflow-related tasks like the execution of code, driving financial transactions, changing system parameters, etc
- LLMs will be highly interoperable – not just with one another but also across multiple modalities like text, video, audio, code and images.
Where in the LLM stack can new players capture value ?
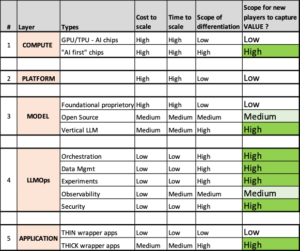
Future LLM Ops category leaders are likely to offer three crucial elements:
- Enhancing AI software development speed is vital. Companies must focus on expediting Generative AI development and simplifying user technology integration.
- Minimise costs and provide concrete ROI. Optimising inference processes can swiftly reduce expenses. Innovations like serverless GPUs exemplify this approach.
- Simplify LLM technology to drive user adoption. Building a solid community fosters user engagement and loyalty.
Some of the key areas where we will see a lot of value being generated are chaining tools (e.g., Langchain), vector databases (ChromaDb, PineCone), training and fine tuning (e.g., Mosaic ML), and observability (e.g., Latticeflow).
- APPLICATION LAYER
The application layer of the GenAI stack has seen 100s of exciting companies spring up in the last year. I (and almost everyone in the investing industry) broadly like to divide modern GenAI applications into 2 broad categories. Thin wrapper AI applications and thick wrapper AI applications.
.a Thin wrapper apps
These applications either enhance an existing workflow or create a new one by simply encasing a general foundation model in wrapper code. This simplified method has emerged as a more accessible and expedited means for businesses to harness and capitalise on generative AI. However, with reduced entry barriers and limited distinctiveness, these generative AI platforms have transformed into commodities lacking a competitive edge. Consequently, the prospects for long-term value generation from these applications appear limited.
b.Thick wrapper applications
To stand out in a competitive landscape where peers utilise generative AI platforms, companies must go beyond mere interaction with a model and focus on delivering a distinctive and enriched user experience. This involves developing “thick wrapper” applications integrating cutting-edge generative models with proprietary technology, enabling finer control and personalised interactions.
Category leader will have a Data as well as workflow MOAT
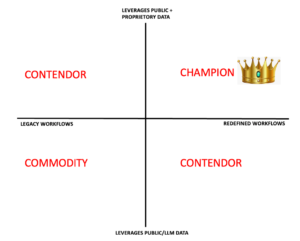
These thick wrapper applications offer unique features that set them apart, providing a competitive edge, enhancing user retention, and ensuring long-term sustainability. Startups that combine a robust data foundation with innovative workflow redesigns position themselves for global success. Such Generative AI-based products are highly differentiated and have the potential to impact how we live and work in the future significantly.
While startups following this model stand out, there are other paths to global success. For instance, companies that reimagine workflows while utilising publicly available data models can still achieve category dominance through efficient execution, speed, and being early movers. Similarly, companies leveraging extensive, proprietary datasets to support existing workflows can establish a valuable intellectual property moat.
This is going to be an exciting ride!
References
https://www.vationventures.com/research-article/understanding-the-generative-ai-tech-stack
https://medium.com/bcgontech/exec-guide-to-investing-in-gen-ai-9232f4ddffea
https://medium.com/bcgontech/exec-guide-to-investing-in-gen-ai-9232f4ddffea
https://www.leewayhertz.com/generative-ai-tech-stack/
https://www.linkedin.com/pulse/gen-ai-moving-vertical-saas-native-sanjay-rao/

Cocktail of Jingoism and Economy Will Lead to a Bad Hangover
As cliched as it may sound, but my blogging debut was actually an accident (not just figuratively, but literally too). A friend of mine damaged his smartphone screen and decided to buy a new top-notch Chinese phone as a substitute.
Much to his surprise, the first image he flaunted on our common WhatsApp group from his 48MP camera was greeted with sarcastic and subtle chants of “betrayer, betrayer”. The participants in the group felt that my friend should have purchased an Apple or Samsung phone instead, to exemplify his “patriotism credentials”. My initial assessment, that the “stop trading with China” lobby, was limited to belligerent television news anchors, has been disproved over the last few days, as many of my friends, from different cross-sections of society, have echoed similar opinions.
I try and explain why such a mindset is self-defeating, and why we are better off in creating a conducive atmosphere so that Chinese goods are substituted “naturally” by creating a better ecosystem for Indian manufacturing. Also briefly touched upon why “Make in India”, in its current form, is a toothless tiger. Feedback and critical inputs are welcome!

10P framework- the mental algorithm behind successful VCs’ INSTINCT
Someone I know via an angel network had invested 15K USD in an Indian e-commerce startup. He exited with a cool 18m USD a few years later in a global buyout. Rob Hayes, a seed round investor in Uber, saw his investment of 510K USD swell to a valuation of 2.5B in 2019 (almost 5000X).
Partners at VC firms and top angel investors are busy people who get 100s of business ideas every week. They often make pencil commitments to invest millions of dollars in startups based on a mere 15-minute presentation. Many VCs claim it’s more of an “instinct”, and less of number crunching and deep analytical frameworks.
However, with time, I have realized that these “snap judgments” are often the result of a deep subconscious process that runs parallelly in a shrewd investor’s mind, while he/she is listening to the presentation. This parallel processing is so deeply ingrained in the investor’s mind, that they may not even be consciously aware of the mental algorithm that’s running.
Over the last couple of years, in advisory roles for VC and angel investments, I have been fascinated by this superfast, “heuristic” process. In an attempt to demystify it- I have created a possible framework that describes the different (and often subconscious) aspects of this mental evaluation- called 10P.